“Independent” Data Marts: Being Stranded on Islands of Data – Part 2
By David Marco
Independent data marts have spread like a disease through many of today’s best and most advanced corporations. The devastating nature of this disease is that it is not easily detected in its initial stages, however if it is not treated that patient’s condition will steadily deteriorate.
This column is the second portion of a three part series on migrating from independent data marts. In part one of this series we examined the characteristics of independent data marts, the flaws in their architecture, and the reasons why they exist. This installment shall focus on the approaches for migration, initial planning and how to identify a migration path.
Approaches to Migration
There are two general approaches for migration; “Big Bang” and “Iterative”. Table 1 summarizes the advantages and disadvantages of each approach.
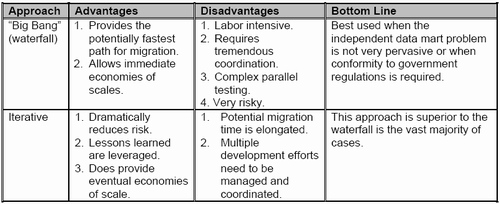
Table 1 : “Big Bang” vs. Iterative Approaches
Big Bang Approach
As the name implies all of the independent data marts will be reengineered simultaneously into a structured data warehousing architecture. There are a couple of advantages to this approach. First, it can provide the fastest path for migration. Often companies will need to change their data warehousing architecture as quickly as possible (regardless of risk) because 1) there is a need to implement additional data warehousing projects that are required to meet government regulations 2) there are data warehousing projects that promise to lend a high return on investment (ROI) and/or 3) because there are currently funds available for the integration effort that might not be available at a later date. Second, this approach allows for immediate economies of scale rather than slowly attaining them in Iterative method. The disadvantages to this approach is that it is labor intensive and requires tremendous coordination. In addition, the “Big Bang” approach is the more complexed of the two to implement and thus provides the highest exposure. Many companies have failed attempted to do big bang integrations.
This approach is best suited when the independent data mart problem is relatively small and not highly complexed. However, when the problem is large the complexity of the migration grows at a tremendous rate.
Iterative Approach
This approach looks to reengineer the independent data marts (one or two data marts at a time) in manageable phases. The advantages to this approach are several. First, it allows a government agency or company to manage and reduce the risk involved in a migration effort. This occurs because the migration can be accomplished in a phased manner thereby increasing the probability of the project’s success. Second, as each project phase is executed lessons are learned and leveraged for subsequent phases. This is very valuable as typically once the first phase is completed the follow up phases run much more smoothly.
The major disadvantage to this approach is that it takes longer to fully complete the migration. This approach is best used when the independent data mart problem is large and too complexed to tackle in a “Big Bang” manner. Having conducted both big bang and iterative independent data mart migrations I strongly prefer the iterative approach.
Initial Planning
Many companies fail in their migration efforts well before they start. The chief reason for this is the lack of initial planning and sponsorship. Attaining executive sponsorship is one of the most important tasks at the onset of the project. This is critical as typically each of the independent data marts have been constructed by autonomous teams in different corporate departments. Therefore having a project champion that has cross-departmental authority is critical for dealing with the political challenges, which are commonplace in these migration efforts.
During the initial planning phases it is important to plan on implementing a meta data repository that can support future data warehousing development efforts and that will provide a semantic layer between the business users and the data warehousing system. The data mart migration provides an outstanding opportunity to implement the meta data repository. Before the data mart migration begins it is best to standardize the data naming nomenclature for the data warehousing system. By implementing standard data naming nomenclature it will aid in the system’s maintenance and provide cleaner and more understandable meta data.
A great deal of research needs to be conducted on the independent data marts before a migration is possible (Table 2: summarizes these tasks). The most important research activity is to understand the business needs that each independent data mart is meeting. Typically multiple independent data marts will exist to meet the same or similar business needs. These situations are common and do suggest a path for migration. The results of this research will illustrate the independent data marts that will be the most difficult to migrate.
During independent data mart migration it is an excellent time to standardize on hardware, and software for the data warehousing project (Table 3: Hardware/Software Classification). For each differing software or hardware platform a company needs to have trained personnel to support it. Therefore, by limiting the redundant software/hardware the corporation reduces the support strain on their IT staff. In addition, standardizing allows for software and hardware purchasing economies of scale can be achieved.
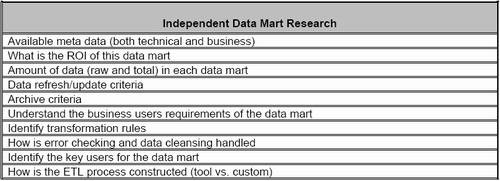
Table 2: Independent Data Mart Migration

Table 3: Hardware/Software Classification
Golden Rule
The central covenant of any independent data mart migration effort is to “Never delivery less functionality to the business users than what they have today”. Generally business users do not react well to spending money on infrastructure because they don’t initially see its value. The key business users need to be educated that a bad system’s architecture leads to a non-scalable and non-flexible system that will eventually need to be rewritten at a very high cost. Therefore, during migration the users must be assured that they will not receive less functionality (information, ease of use, and response time) than what they are currently receiving today.
Identifying a Migration Path
There are several activities that are necessary to conduct before a migration path will be evident.
Create Your Own Spaghetti Chart
First, diagram out the current data warehousing architecture. This is critical for identifying which legacy systems are feeding which independent data marts and for showing the problems with this architecture (or lack thereof).
Figure 1: Diagram Current Data Warehousing Architecture
Identify Redundant Data
Often independent data marts will be sourced from the same legacy systems. By targeting independent data marts with the same source data often multiple independent data marts can be removed with minimal extra effort. Identifying redundant data often suggests a migration path.
Figure 2 illustrates existing independent data marts for a company. In the schematic both the Finance and Marketing data marts are being sourced from the same legacy systems. This suggests that it might be wise to target both of these data marts for initial migration (assuming the Iterative approach is being used).
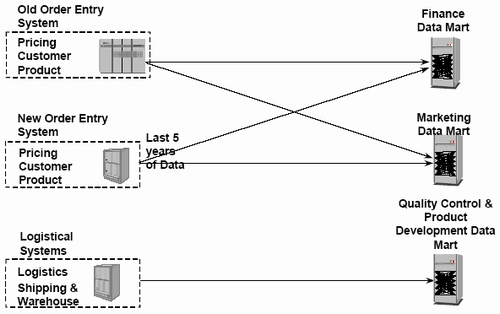
Figure 2: Identifying Redundant Data Sources
Identify Paths of Least Resistance
Data
It is important to target those independent data marts whose data will most likely be used in future data warehousing efforts. By targeting these data marts first it will ease the task of keeping all new data warehousing development activity in the new architected environment.
The next step is to identify those data marts whose transformation rules are known and documented. Understand that even the best documented transformation rules will have gaps. Moreover, even those marts that have been built using extraction, transformation and load (ETL) tools have meta data (documentation) gaps. For example, ETL tools many times provide the functionality to call user exits that are hand-coded programs. The processes performed by these user exits will not be captured in the ETL tool’s meta data stores. If documentation does not exist for a mart then programmers will need to manually analyze each of the ETL program’s code to extract the transformation rules. Manually analyzing code to extract transformation rules is a very time consuming and expensive activity.
Political
It will be critical to obtain support from the current independent data mart IT teams and business users. Identify those data mart teams most likely to work cooperatively with the centralized data warehousing team. Recognize the strengths and weaknesses of those teams that can and will provide the most aid. If a particular data mart team/business users are not willing to assist with the migration effort it is best to work around these teams by delaying the migration of their particular data mart. If this is not an option then utilize your executive sponsorship to “motivate” this group to provide their support.
Understand your team’s strengths and weaknesses
Keep in mind that any team will have its stronger and weaker areas of knowledge/skill. As much as possible keep your team’s areas of weakness off of the critical path. Any mission critical team weaknesses need to be shored up with internal members from the other data mart teams or from outside vendors.
In next month’s third and concluding portion of this column I will present a case study illustrating how a corporation can migrate from independent data marts into an architected solution.