Modeling Meta Data
By David Marco
Building a meta data repository is no longer an option for corporations, but an absolute requirement. One of the most important tasks in the development of a repository is the construction of the meta model (a physical database that holds meta data). Building the meta model can be a difficult task at the best of times. There are many factors to consider, such as what types of meta data you need to store, how you are going to store it, who has access to it, and who is going to build it. As we go through this article we’ll discuss the types of information that you need to start designing your meta model.
As is the case in most things, there is no silver bullet that answers every possible meta data requirement and is still easy to use and understand. We’ll examine two ways of modeling a meta data model — generic object and traditional relational. In order to understand which approach is best for your company, we’ll walk through the differences of using each approach.
The Meta Model
A meta model is the physical database model that is used to store all of the meta data. A meta model differs from typical models in that it contains the business functions and rules that govern the data in our systems. Therefore, a meta model is simply a model created at a higher level of abstraction than the thing being modeled. In this case, you make a model of the business functions and rules that form the data we use every in our corporation. In a nutshell, this is a model to store information about your data. Of course, as with most things, there is a tradeoff between being able to store anything and not having to change the meta model versus being able to store only pre-determined things and having to frequently change the model. In a traditional model, you have entities (tables) that have relationships to other entities. These entities form the basis for the physical design of the database. On the other hand, in an object model your model comprises a fixed number of entities that hold the relationships and entity information in their structure.
The traditional model starts with a more complex model design, but has less complex programs that use it. The object model has a very simple model design, but all of the “smarts” go into the programs that use it. To determine which model is better suited for your needs, you need to examine the specifics of your organization (see Table 1).
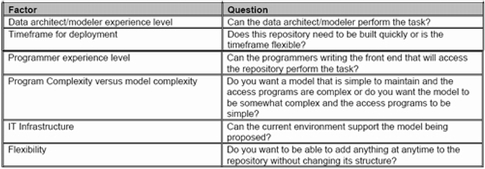
Table 1: Influential Factors in Your Choice of a Model
Summary
As you can see, there is a lot that has to be done to build a quality meta model that can grow with your company’s needs and still remain flexible. In this article, we described the two types of models that can store meta data (object and traditional) and have examined the factors and rules that help us decide on a model type for our company. Things like project schedules, model flexibility, and staff experience levels all play a role in selecting a model type.
Both types of models have advantages and disadvantages (see Table 2 for a summary). The object model is more scalable and flexible than a traditional model, but also less intuitive and harder to understand by looking at it. This is because the object model stores in its tables the actual structure of the meta data that you are storing. The traditional model, on the other hand, contains many more entities and relationships, but is easier to understand and work with than an object model. The choice of an appropriate model type depends on your particular environment and user requirements for the meta data and requires careful research on your part to make an informed decision.
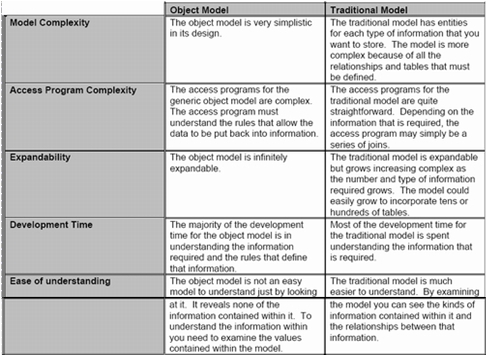
Table 2: Object Model versus Traditional Model