Meta Data Repositories: Where We’ve Been And Where We’re Going
By David Marco
I thought that it would be valuable to take a look back and see where meta data management and repositories have come from and where the meta data management and repository industry are headed. As the old saying goes, “We’ve come a long way baby!”
Many people believe that meta data and meta data repositories are new concepts, but their origins date back to the early 1970s, or in more general terms back to the first days of computing. When we first started building computer systems, we realized that there was a “bunch of stuff” (knowledge) that was absolutely necessary for building, using, and maintaining information technology (IT) systems. We learned very quickly that meta data existed throughout all of our organizations (see Figure 1). Meta data is stored in our systems, technical processes, business processes, policies and people. Essentially, we knew that we had no place to put any of this information (meta data). At this point, we realized that we needed data about the data that we were using in our computer systems.
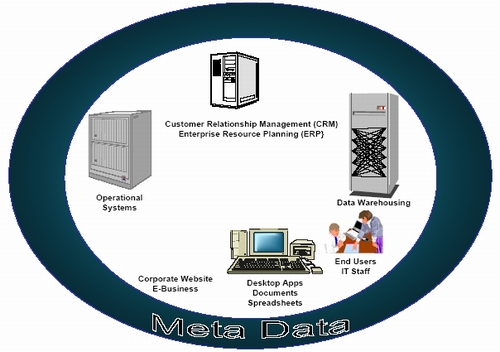
Figure 1: Meta Data Points
Early Commercial Products
When the first commercial meta data repositories appeared in the mid-1970s, they were called “data dictionaries”. These data dictionaries were very “data” focused and less “knowledge” focused. They provided a centralized repository of information about data, such as meaning, relationships, origin, domain, usage, and format. Their purpose was to assist database administrators (DBAs) in planning, controlling, and evaluating the collection, storage, and use of data. One of the challenges that meta data repositories have today is differentiating themselves from data dictionaries. While meta data repositories perform all of the functions of a data dictionary, their scope is far greater. The early meta data repositories (data dictionaries) were mainly used for defining requirements, corporate data modeling, COBOL (common business-oriented language) and PL/1 (programming language one) data definition generation and database support (see Figure 2).

Figure 2: 1970s: Data Dictionaries Masquerading as Repositories
Later a new phenomenon would enter the world of IT and forever change it…the personal computer (PC). When PCs burst onto the business scene, they changed the way companies worked and fueled tremendous gains in productivity. CASE (computer aided software engineering) was one of the productivity gains. CASE tools were software applications that automate the process of designing databases, applications, and software implementation. These design and construction tools stored data about the data (meta data) that they managed (see Figure 3).
It didn’t take long before the users of the CASE tools started asking their vendors to build interfaces to link the meta data from various CASE tools together. The CASE tool vendors were reluctant to build these interfaces because they believed that their own tool’s repository could provide all of the necessary functionality, and, understandably, they didn’t want companies to be able to easily migrate from their tool to a competitor’s tool. Nevertheless, some interfaces were built, either using vendor tools or dedicated interface tools.
In 1987, the need for CASE tool integration triggered the Electronic Industries Alliance (EIA) to begin working on a CASE data interchange format (CDIF), which attempted to tackle the problem by defining meta models for specific CASE tool subject areas by means of an object oriented entity relationship modeling technique. In many ways, the CASE Data Interchange Format (CDIF) standards came too late for the CASE tool industry.
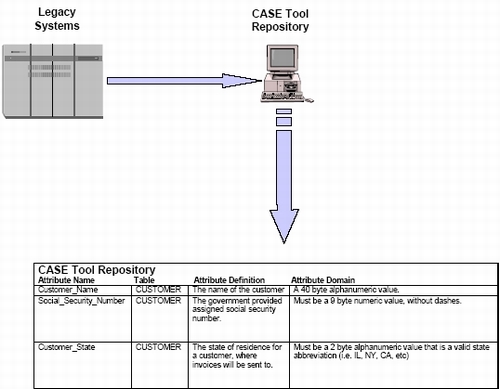
Figure 3: 1980s: CASE Tool-Based Repositories
During the 1980’s, several companies, including IBM, announced mainframe-based meta data repository tools. These efforts were the first meta data initiatives, but their scope was limited to technical meta data and almost completely ignored business meta data. Most of these early meta data repositories were just glamorized data dictionaries, intended, like the earlier data dictionaries, for use by DBAs and data modelers. In addition, the companies that created these repositories did little to educate their clients in the use of these tools. Few companies saw much value in these early repository applications.
In the 1990’s, decision support emerged and soon convinced business managers of the value of a meta data repository, expanding the scope of the early repository efforts well beyond that of data dictionaries.
The meta data repositories of the 1990’s featured a client-server paradigm as opposed to the traditional mainframe platform on which the old repositories operated. The mainframe vendors viewed these new repositories as a threat since they greatly eased the task of migrating from a mainframe environment to the new and popular client-server architecture. The multiplicity of decision support tools requiring access to meta data re-awakened the slumbering repository market. Vendors such as Rochade, RELTECH Group, and BrownStone Solutions were quick to jump into the fray with new repository products. Many older, established computing companies recognized the market potential and attempted, sometimes successfully, to buy their way in by acquiring these pioneer repository vendors. For example, Platinum Technologies purchased RELTECH, BrownStone, and LogicWorks, and was then swallowed by Computer Associates in 1999.

Figure 4: 1990s: Decision Support Meta Data Repositories
Where Are We Headed?
Meta Data Management Moving Mainstream
Currently meta data management and meta data repository development is at a very similar stage as data warehousing was in the early 1990’s. In the early 1990’s, people like Bill Inmon were essential in articulating the value of building data warehouses. At that time companies were beginning to listen and were starting to build their data warehouse investments. Meta data repositories are moving in much the same direction today. In fact at Enterprise Warehousing Solutions (EWS) we are doing more meta data repository development now than at any other point in our company’s history. Companies are beginning to realize that they need to make significant investments in their repositories in order for their systems to provide value.
Meta Data Repositories Providing Knowledge Management
All corporations are becoming more intelligent. Businesses realize that to attain a competitive advantage they need their IT systems to manage more than just their data; they must manage their knowledge (meta data). As a corporation’s IT systems mature, they progress from collecting and managing data to collecting and managing knowledge. Knowledge is a company’s most valuable asset and a meta data repository is the key to managing a company’s corporate knowledge (for more information on this topic see “A Meta Data Repository Is The Key To Knowledge Management”, David Marco).
Maturing Meta Data Integration Products
There has been no tougher critic of the meta data integration vendors than myself and I still believe that these vendors are neglecting their most important user: the business user. With that being said, in the past year I also have seen across-the-board improvements by almost all of the vendors in this area. New vendors like Data Advantage Group are coming onto the meta data integration scene with new and exciting products. In addition, the more traditional meta data repository vendors like Computer Associates and Allen Systems Group have all dramatically improved their product lines.1
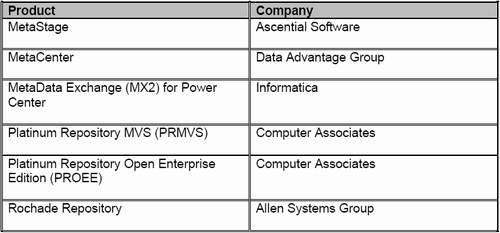
Table 1: Meta Data Integration Vendors
Meta Data Repositories/Management Continue Moving Mainstream
To illustrate how far meta data repository development has come, around 9 months ago I was asked to speak for one day to a group of approximately 15 IT senior vice-presidents of banks. their number one technology issue was meta data! When I spoke on meta data many years ago, we were lucky to have 15 IT developers in a talk. In most every Fortune 500 company there exists massive amounts of redundant data (I have experienced that the average company has 4 fold needless data redundancy), needlessly redundant systems, and tremendous data quality problems. Fortunately, executive management are starting to realize that these problems result in a tremendous cost drain for their companies. These same people are looking to control the costs of their IT departments through the use of meta data repositories. As a result, meta data repositories and meta data management are continuing to move up corporations’ IT priority lists.
1 If you are assessing these vendor’s products you may be interested in a third-party evaluation. Information on EWS’ 150-page comparative study of these producor by emailing ts can be found on the EWS website at www.EWSolutions.com or by emailing Info@EWSolutions.com decision support technologies (866) EWS-1100. He may be reached directly at (708) 233-6330 or via email at DMarco@EWSolutions.com