Advanced Meta Data Architecture
By David Marco
Corporations are demanding more and more functionality from all of their IT (information technology) systems and meta data repositories are no exception to this rule. In previous articles I have discussed the architectural concepts that are be applicable to most any meta data repository effort. This month’s column will address the more complexed architectural challenges that arise with implementing a meta data repository that requires more advanced functionality. While most repository initiatives do not attempt to implement these features, they are certainly the type of functionality that is getting demanded from corporations. It is also important to note that these concepts can be implemented separately or in-conjunction with one another.
Bi-Directional Meta Data
Typically the architecture of a meta data repository is one directional. Meta data sources (i.e. data modeling tool, extraction/transformation/load tools, etc.) flow into the repository and are integrated for various needs. A bi-directional meta data architecture allows for meta data to be changed in the repository and then be feed back from the repository into it’s original source. For example, a user could go through the repository and change the name of an attribute in one of the decision support system’s data marts. This change would then be feed back into the supporting data modeling tool to update the physical model for that specific data mart.
This architecture is highly desirable for two key reasons. First, it allows vendor tools to share meta data. This is especially desirable in the decision support marketplace. Most corporations that have built a decision support system did so with “best-of-breed” tools, as oppose to integrated tool sets that are supplied by one vendor. However, these tools are not integrated with one another and do not communicate easily. Even those tools that can be integrated traditionally require a good deal of resource intensive manual programming in order to share data. This is why both Microsoft with the Open Information Models (OIM) and Oracle with the Common Warehousing Metadata (CWM) have looked to resolve this situation by providing a meta data architecture that third party vendor tools can plug into to communicate (share data) with one another. Second, bi-directional meta data is attractive to corporations that want to implement a meta data repository on an enterprise-wide scale. By enterprise-wide meta data I mean companies that want their meta data repository to store information on all of their IT systems, not just their decision support systems. This would allow a corporation to make global changes in the meta data repository and have those changes sweep throughout the enterprise.
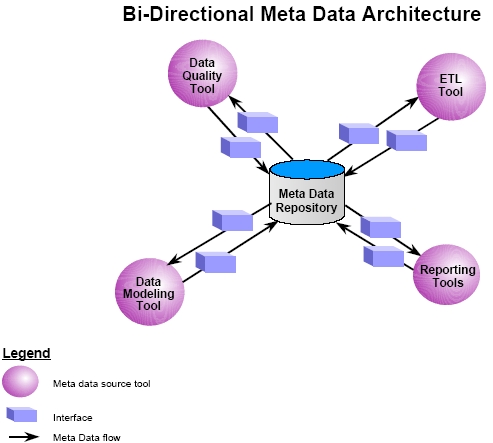
Figure 1: Bi-Directional Meta Data Architecture
There are three obvious challenges to implementing bi-directional meta data. First, is it forces the meta data repository to contain the latest version of the meta data source that it will feed back into. Second, someone can be making a change to the meta data in the repository and at the same time someone else can be making a change to the same meta data at its source. These situations must not only be systematically trapped but also resolved. Third, additional sets of program/process interfaces need to be built to tie the meta data repository back to the meta data source.
Closed Loop Meta Data
A closed loop meta data architecture allows for the repository to feed its meta data back into a corporation’s operational systems. This concept is similar to the bi-directional meta data architecture in that the meta data repository is feeding it’s information (meta data) into other applications, or in this case operational systems. The closed loop meta data architecture is gaining more and more notoriety in corporations that want to implement a meta data repository on an enterprise-wide level. This would allow a corporation to make global changes in the meta data repository and have it sweep throughout the operational systems of an enterprise.
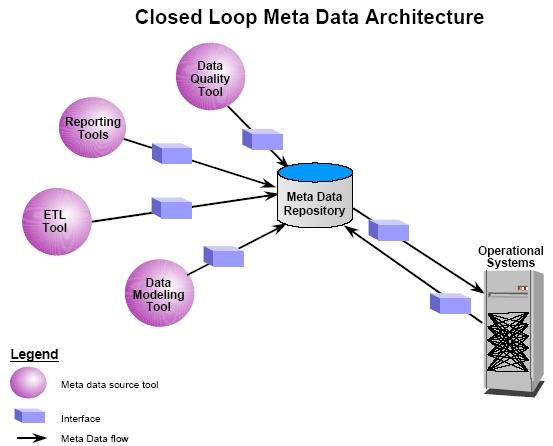
Figure 2: Closed Loop Meta Data Architecture
The closed loop meta data architecture adds some additional complexity to the meta data repository initiative. First, if the meta data that will be feed from the repository to the operational system can also be maintained in the operational system this would require that the meta data repository contain the latest version of that operational system’s meta data. If not than the user of the repository could not be sure of updating the latest copy of the meta data. Second, someone can be making a to the meta data in the repository and at the same time someone else can be making a change to the operational system. These conflicts must not only be systematically trapped, but also resolved. Third, program/process interfaces need to be built to tie the meta data repository back to operational systems. Currently few companies are attempting this architectural technique, however it is a natural progression in the architecture of meta data repositories.