Moving Your ETL Process Into Primetime (Part III)
By
This is the final article in a three-part series. In Part I, we discussed the initial load, the historical load, and the ongoing incremental load processes. In Part II, we examined some important considerations when designing the extract, transform, and load programs. In this issue, we will conclude Moving Your ETL Process Into Primetime with a discussion of designing the ETL process flow and staging area
Designing the ETL Process Flow
Source-to-Target Mapping Document
Before the ETL process flow can be designed, the detailed ETL transformation specifications for data extraction, transformation, and reconciliation have to be developed, given that they will dictate the process flow. A common way to document the ETL transformation specifications is in a source-to-target mapping document, which can be a matrix or a spreadsheet, as illustrated in Table 1.
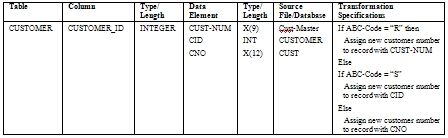
Table 1. Example of a Source-to-Target Mapping Document
The source-to-target mapping document should list all BI tables and columns and their data types and lengths. It should map the applicable source data elements to the columns, along with their data types and lengths, and it should show the source files and source databases from which the source data elements are being extracted. Finally, and most importantly, the document should specify the transformation logic for each column. This document can then be used to create the actual programming specifications for the ETL developers or to create instructions (technical meta data) for the ETL tool.
ETL Process Flow Diagram
Once the source-to-target mapping document has been completed, the ETL lead developer, with the help of the database administrator and the data quality analyst, must design the ETL process flow, as illustrated by the example in Figure 1.
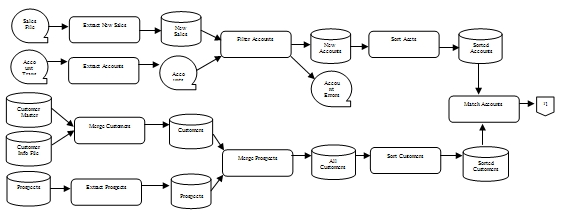
Figure 1. Sample ETL Process Flow Diagram
The purpose for the ETL process flow diagram is to show the process dependencies between all extracts, sorting and merging utilities, transformations, temporary work files or tables, error-handling processes, reconciliation activities, and the load sequence. The ETL programs, or ETL tool modules, will have to run in this sequence.
-
Extracts: There are often operational interdependencies among several source files and source databases from which data is being extracted. For example, updates to the Sales File have to be completed before the Account Transaction File can be processed. These interdependencies have to be understood because they may affect the timing and the sequence of running the ETL extract programs.
-
Sorting and merging utilities: Almost every step requires the extracted data to be sorted in a particular fashion so that it can be merged before further processing can occur. Sorting can also greatly improve load performance.
-
Transformations: Most of the data has to be transformed for a variety of reasons. It is important to examine the most opportune times to perform the transformations. Remember that there is only one coordinated ETL process for the BI environment. Therefore, transformations applicable to all source data, such as data type and code conversions or data domain enforcements, should be performed early in the ETL process flow. Transformations specific to a target database, such as aggregation and summarization for a specific data mart, should occur toward the end of the ETL process flow.
-
Temporary work files or tables: Sorting, merging, and transforming require a lot of temporary storage space to hold the interim results. These temporary work files and tables can be as large or larger than the original extracts. Furthermore, these temporary work files and tables are not really “temporary.” Plan to have that space available for your staging area permanently.
-
Error-handling processes: During the ETL process many errors are detected as the data-cleansing specifications are applied to the source data. Depending on the stated business rules for each data element, the ETL programs will either accept, or transform, or reject the erroneous data and will report the errors. If error reports are created or erroneous records are rejected into a suspense file, they should be shown on the ETL process flow diagram.
-
Reconciliation activities: Every program module that manipulates data should produce reconciliation totals. This can be in the form of input and output record counts, specific domain (data values) counts, or amount counts. Record counts are sufficient for extract, sort, and merge modules. Domain counts are appropriate for more complicated transformation specifications, such as separating data values from one source data element into multiple target columns, as shown in Figure 2. Amount counts are usually performed on all amount data elements, whether they are moved as-is, transformed into a new format, or used in a calculation.
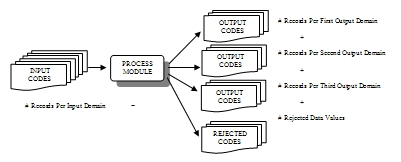
Figure 2. Domain Count
-
Load sequence: It is necessary to determine the sequence in which the tables have to be loaded because of their potential interdependencies and because of a possible recursive relationship on a table. For example, the PRODUCT dimension table may have to be loaded before the SALES table is loaded, if RI is turned on and if the sales data references products. Other tables may be loaded in parallel, which can greatly improve the speed of the load process.
Staging Area
A staging area is the place where the ETL process runs. It refers to dedicated disk space, ETL program libraries, temporary and permanent work files and databases – even a dedicated server. The staging area can be centralized or decentralized. For example, it can be a central mainframe staging area if most of the source data is in flat files on a mainframe. It can also be on a dedicated server onto which the source data is loaded. Many times the staging area is decentralized. For example, a convoluted mainframe file with many redefines and occurs clauses may have to be flattened out with a COBOL program in a staging area on the mainframe before it is downloaded to a staging area on a UNIX box for further processing by an ETL tool.
Do not create a separate staging area for each data mart. A decentralized, coordinated staging area is not the same thing as separate, uncoordinated staging areas for different BI databases and different BI applications!
The ETL process is by far the most complicated process to be designed and developed in any BI Application. Since there is only one [logical] coordinated ETL process for the BI environment, expanding the ETL programs with each new BI application becomes very complicated, and regression testing requires more and more time. For these reasons, most organizations prefer to use an ETL tool for all or some of the ETL process, especially for the extract and transformation processes.
Conclusion
Building a robust and sustainable ETL process for BI applications is not a trivial effort. When developing the three sets of load programs (the initial load, the historical load, and the incremental load programs), you must carefully design three types of programs for each set: the extract programs, the transformation programs, and the load programs. In addition, the coordinated ETL process flow and staging area must be created in such a way that they are easily expandable to feed future additional BI databases. You can read more about the ETL process and about other development steps, such as application prototyping, data analysis, or data mining in my book Business Intelligence Roadmap, The Complete Project Lifecycle for Decision-Support Applications, published by Addison Wesley, 2003.
About the Author
Ms. Moss is president of Method Focus Inc., a company specializing in improving the quality of business information systems. She has over 20 years of IT experience. She frequently lectures and presents at conferences in the United States, Canada, Europe, Australia, and Asia on the topics of Data Warehousing, Business Intelligence, Customer Relationship Management, Information Quality, and other information asset management topics, such as data integration and cross-organizational development. She provides consulting services in data warehouse and business intelligence assessment, spiral methodologies, project management, data administration, data modeling, data quality assessment, data transformation and cleansing, as well as meta data capture and utilization.
Ms. Moss is co-author of three books: Data Warehouse Project Management, Addison Wesley 2000; Impossible Data Warehouse Situations, Addison Wesley 2002; and Business Intelligence Roadmap: The Complete Project Lifecycle for Decision Support Applications, Addison Wesley, 2003. Her articles are frequently published in DM Review, TDWI Journal of Data Warehousing, Teradata Magazine, Cutter IT Journal, www.ewsolutions.com, andwww.businessintelligence.com. Her white papers are available through the Cutter Consortium. She can be reached at methodfocus@earthlink.net