Data Analysis
By
This article is excerpted from the book Business Intelligence Roadmap: The Complete Lifecycle for Decision Support Applications (Addison-Wesley, 2003). Copyright Larissa T. Moss, Shaku Atre, Addison-Wesley.
For many organizations, a business intelligence (BI) initiative is the first attempt at bringing business data together from multiple sources in order to make it available across different departments. Organizations that use a traditional system development approach on their BI or data warehouse (DW) projects usually run into severe source data quality problems too late in the life cycle; namely when they try to implement the extract/transform/load (ETL) process. The reason for the delayed discovery of dirty data is that traditional methodologies have – at best – a systems analysis phase for application functions, but not a business-focused data analysis phase for the underlying source data.
Business-focused data analysis is different from systems analysis. Traditionally, the activities performed during systems analysis are geared toward producing a design decision for the system to be built. The activities performed during business-focused data analysis are geared toward understanding and correcting the existing discrepancies in the business data, irrespective of any system design or implementation method. Business-focused data analysis involves two methods:
- Top-down logical data modeling for integration and consistency,
- Bottom-up source data analysis for standardization and quality.
Top-Down Logical Data Modeling
When discussing logical data modeling, two distinct data models must be described:
- Project-specific logical data model
- Enterprise logical data model
Project-Specific Logical Data Model
The most effective technique for discovering and documenting the single cross-organizationally integrated and reconciled view of business data is entity-relationship (E-R) modeling, also known as logical data modeling. The normalization rules of E-R modeling are applied during top-down data modeling as well as during bottom-up source data analysis. Using normalization rules, along with other data administration principles, assures that each data element within the scope of the DW project is uniquely identified, correctly named, properly defined, and that its domain (content) is validated for all business people who are creating and using this data. That means that the normalized project-specific E-R model yields a formal representation of the data, as it exists in the real world (as opposed to in a database), without redundancy and without ambiguity.
A logical data model, or entity-relationship model, is process independent. That means its structure and content are not influenced by any type of database, access path, design, program, tool, hardware, or reporting pattern. In other words, a logical data model is a business view, not a database view or an application view. Therefore, a unique piece of data, which exists only once in the real business world, also exists only once in a logical data model.
Enterprise Logical Data Model
It is the responsibility of an enterprise architecture (EA) group, or of data administration if the organization does not have an EA group, to merge the project-specific logical data models into an integrated and standardized enterprise logical data model, as illustrated in Figure 1.
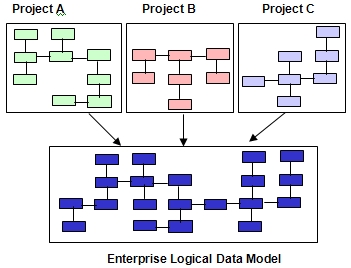
Figure 1 Merging Project Models into an Enterprise Model
This enterprise logical data model is never constructed all at once, nor is it a prerequisite for BI projects to have a completed one. Instead, the enterprise logical data model evolves over time and may never be completed — and does not need to be completed because the objective of this process is not to produce a finished model, but to discover and resolve data discrepancies. These data discrepancies exist en masse among stovepipe operational systems and are the root causes for the current inability to provide integrated and consistent cross-organizational information to the business community. The discovery of these discrepancies should be embraced and celebrated by the BI project teams, especially by the business people, because data quality problems are finally being addressed and resolved. Gaining control over disparate and redundant data is, after all, one major purpose of any BI initiative.
Logical Data Modeling Participants
Logical data modeling sessions are typically facilitated and led by a data administrator who has a solid business background. If the data administrator does not have a good understanding of the business, a subject matter expert must assist him or her in this task.
The business representative assigned to the BI project is an active participant during the modeling sessions, as are the data owners. Data owners are the business managers who have authority to establish business rules and set business policies for those pieces of data that are originated by their department. When data discrepancies are discovered, it is the data owners’ responsibility to sort out the various business views and to approve the legitimate definition and usage of their data. This data reconciliation process is – and should be – a business function, not an IT function, although the data administrators, who usually work for IT, facilitate the discovery process.
Systems analysts, developers, and database administrators should also be available to participate in some of the modeling sessions on an as-needed basis. These IT specialists are some of the data stewards. They maintain the organization’s applications and data structures, and they are often most knowledgeable about the data – how and where it is stored, how it is processed, and ultimately how it is used by the business people. In addition, they often have in-depth knowledge of the accuracy of the data, how it relates to other data elements, the history of its use, and how the content and meaning of the data has changed over time. It is important to obtain the commitment from these IT resources since they are often busy “fighting fires” and working on enhancements to the operational systems.
Bottom-up Source Data Analysis
Data analysis cannot stop with top-down logical data modeling because the source data often does not follow the business rules and policies captured during the modeling sessions. If bottom-up source data analysis is not performed at the same time, the data problems and business rule violations will not be discovered until the ETL process is implemented. And worse, some data quality problems would not be discovered at all until after implementation, and then only if business people complained about them.
Bottom-up source data analysis is a prerequisite for source-to-target data mapping and for creating complete ETL specifications because source data mapping must pass not only the usual technical data conversion rules but also the business data domain rules and the business data integrity rules.
Technical Data Conversion Rules
Any time data is mapped from one system to another, whether for traditional system conversion or for source to target mapping in DW applications, the following technical rules must be observed.
- The data types of the source data element must match the data types of the target data element.
- The data length of the source data element must be adequate for being moved, expanded, or truncated into the target data element.
- The programs manipulating the data element must be compatible with the content of the data element.
Business Data Domain Rules
A much larger effort of source data analysis – and often ignored – revolves around business data domain rules. These rules are more important to the business community than the technical data conversion rules. A source data element can meet all three technical data conversion rules but its contents can still be wrong. Business data domain rules are rules about the semantics of data content. They are used to identify and correct data domain violations, such as:
- Missing data values (big issue for business people using BI applications)
- Default values; for example 0, 999, FF, blank
- Intelligent “dummy” values, which are specific default (or dummy) values that actually have a meaning; for example Social Security Number of 888-88-8888 being used to indicate that the person is a non-resident alien
- Logic embedded in a data value; for example: checking account number 0773098875, where 0773 is the branch number and 098875 is the actual account number at that branch
- Cryptic and overused data content; for example: the values “A, B, C, D” of a data element define type of customer, while the values “E, F, G, H” of the same data element define type of promotion, and the values “I, J, K, L” define type of location
- Multi-purpose data elements, i.e. programmatically and purposely redefined data content; the most obvious example being the “redefines” clause in COBOL statements
- Multiple data elements embedded in, concatenated across, or wrapped around free-form text fields; for example: Address Lines 1 through 5 containing name and address data elements:
Address Line 1: Brokovicz, Meyers, and Co
Address Line 2 hen, Attorneys at Law
Address Line 3 200 E. George Washington
Address Line 4 Boulevard, Huntsville
Address Line 5 OR 97589
Business Data Integrity Rules
Similar to business data domain rules, business data integrity rules are much more important to improving information quality than are the technical data conversion rules. These rules govern the semantic content among dependent or related data elements, as well as constraints imposed by business rules and business policy. Examples of violations to business data integrity rules are:
- Contradicting data content between two or more data elements; for example: Boston, CA (instead of MA)
- Business rule violation; for example: Date of Birth = 05/02/1985 and Date of Death for the same person = 11/09/1971
- Reused primary key (same key value used for multiple object instances); for example: two employees with the same employee number
- No unique primary key (multiple key values for the same object instance); for example: one customer with multiple customer numbers
- Objects without their dependent parent object; for example: job assignment points to employee 3321, but there is no employee 3321 in the employee database
- A real-world relationship between two data objects that cannot be built for the BI database due to lost business interrelationships among operational systems
Every critical and important data element must be examined for these defects, and a decision must be made on whether and how to correct them. The business representative on the BI project team makes that decision after discussing the impact of the cleansing effort with the project manager and the core team.
Business-focused data analysis activities are not database design activities. They should be performed prior to database design. Otherwise, the result is often a haphazard system analysis activity limited to technical conversion rules and producing BI data with many undetected data domain and data integrity violations.
Conclusion:
Organizations often do not want to take the time to perform rigorous data analysis, which involves top-down logical data modeling and bottom-up source data analysis. They see that as a waste of time. They judge the success of a BI project by the speed in which it gets delivered, rather than by the quality of its deliverable. As a result, organizations often end up with stovepipe data marts, which are populated “suck and plunk” style with almost the exact same data, and the exact same data impairments they have on their source files and source databases. Instead of eliminating their existing data problems, they just add to it – because now they have a number of additional redundant and inconsistent BI databases and applications to maintain.
About the Author
Ms. Moss is founder and president of Method Focus Inc., a company specializing in improving the quality of business information systems. She has over 20 years of IT experience with information asset management. She frequently lectures and presents at conferences in the United States, Canada, Europe, Australia, and Asia on the topics of Data Warehousing, Business Intelligence, Customer Relationship Management, Information Quality, and other information asset management topics, such as data integration and cross-organizational development. She provides consulting services in data warehouse and business intelligence assessment, spiral methodologies, project management, data administration, data modeling, data quality assessment, data transformation and cleansing, as well as meta data capture and utilization.
Ms. Moss is co-author of the books: “Data Warehouse Project Management,” Addison Wesley 2000; “Impossible Data Warehouse Situations,” Addison Wesley 2002; and “Business Intelligence Roadmap: The Complete Project Lifecycle for Decision Support Applications,” Addison Wesley, 2003. Her articles are frequently published in The Navigator, Analytic Edge, TDWI Journal of Data Warehousing, Cutter IT Journal, and DM Review. She also publishes executive reports (white papers) through the Cutter Consortium.
She can be reached at methodfocus@earthlink.net