Now You See It . . . The Vanishing User Interface And The Ubiquity Of Information
By Ian Rowlands
Introduction
The history of technology is the history of absorptions and extinctions. No matter what the technology or tool, its usefulness — or lack thereof — either leads the technology towards a kind of invisible ubiquity if the technology is successful or absolute extinction if the technology becomes obsolete. Take two basic (and successful) examples: the automobile and the telephone. In the early days of telephone use, people needed a specially-trained operator to make a phone call. The user would approach the phone, which may or may not be in the user’s home environment, and crank it, ringing a local operator who would facilitate the end user’s call. At this early stage the technology required a user, several obvious pieces of technology and a facilitator just to function. The technology itself was a clear, complex and separate system of tools that existed outside the end user. The same was true of the automobile in its early days. During the early stages of the adoption of the automobile, owners would need a driver and mechanic (perhaps the same person) to maintain and operate the vehicle so that the end user (the passenger) could gain the benefit of the technology (a ride).
Over time, as technology has improved and become more incorporated into our daily lives, the operator and the driver-mechanic have disappeared. The user interfaces for cell phones and cars are virtually invisible. Cell phones and automobiles have become almost organic outgrowths of their user-operators, vanishing into the ambient environment of the end user. Today drivers and cell phone users spend a considerable sum of money personalizing these items, further incorporating them into their ambient reality.
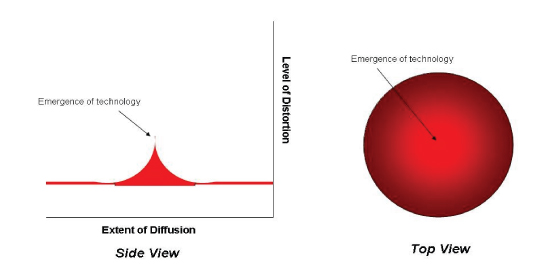
Figure 1: The Technology Diffusion Model: As new technology is adopted, its disruptive effects and distribution can be measured just as a drop of water makes a backsplash and a ripple in a pond. A higher spike means more distortion of the market while a wider distribution means broader distribution within that market. The higher the peak, the more disruptive the technology. Likewise, the bigger the circle the larger the potential market. On this chart, the more intense the color the more visible the technology is to users. Typically, as a product penetrates its market it becomes less disruptive, and therefore, less “visible” to users.
IT Becomes Transparent
Information technology is no different from any other technology in its patterns of adoption and integration into human life. As human beings began to use computers to organize, synthesize and contextualize information, people constructed separate information tools to help facilitate these needs. Traditional relational databases held information in carefully created structures and were built, maintained and cared for by information analysts. Each relationship within these information schemas was created manually by the information analysts. These specialists were the “operators” in this system, creating an important layer between the end-user who needed meaningful information and the data itself. The information analysts would produce reports for the end-users, based on carefully constructed queries.
At this stage IT information can be thought of as checkers on a checkerboard. The pieces are forced into the grid structure of the report. Information itself is in slots and is organized in a highly linear fashion. While this kind of inflicted structure can produce wonderful, useful reports, it does not produce readily available data that is easily cross-referenced in a variety of perspectives. The ways that you are allowed to move from square to square are extremely limited. In fact for each perspective in this model, there would usually have to be another, different report – and a new game of checkers.
Over time, the limitations of this model have been pushed repeatedly by knowledge workers themselves. For these knowledge workers, access to the appropriate context to information is often just as important as the information itself. They need a consistently flexible way to get to as much data as possible in as many ways as possible as quickly as possible. This has led to the creation of metadata repositories to provide perspective and context for data.
Metadata is the Next Step
By using metadata to categorize and organize information into a flexible and adaptable rational schema, knowledge workers are no longer dependant upon information analysts to manually construct relationships between data items or create elaborate queries to get the right information in the proper perspective. Each piece of information in this model comes equipped with its own metadata categories and headings that enable information to be contextualized almost automatically. To use a common metaphor, objects that are encoded with appropriate metadata carry with them the DNA code for their own context and perspective, and, therefore, do not require the manual creation of relationships.
Think of the data in the metadata model as spaghetti sauce poured on noodles. Rather than following a rigid, squared-off pattern of a waffle-grid to attempt to find the right information in the right perspective, all a knowledge worker must do is pull on one strand of spaghetti and all of the appropriate information will be extracted, stuck to the single piece of metadata spaghetti in whatever way may be the most meaningful to the knowledge worker. In this model information permeates the environment – it is not just pooling in the grid pattern. Here information itself is becoming more of an environmental element than an external object.
Look again at the model of the Evolution of Metadata from last month’s article (Figure 2, below). It is clear that the position of the knowledge worker today is, in fact, quite similar to that of the user of the telephone or the automobile. As the use of available technology increases and the technology itself develops and responds to the needs of the end-user, the line between that end-user and the technology blurs. The technology becomes faster and more flexible; expected and transparent.
In the case of the knowledge worker, the purely technical information user interface is being absorbed into just another function of the knowledge worker. Over time this change will become more entrenched.
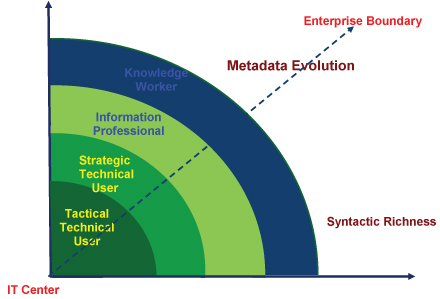
Figure 2: The Evolution of Metadata: As the use of metadata has evolved, the semantic and syntactic richness of the metadata itself has necessarily increased. Commensurate with this evolution the context of the metadata has moved from the purely technical IT center to the more business-oriented boundaries of the enterprise.
Increasingly knowledge workers are moving away from a position that could be defined as purely technical – producing requested reports and keeping an eye on huge databases — and moving towards alignment with more real-world business knowledge – organizing information in meaningful ways and making it more readily available to more people on a self-serve basis. Just like the operators and the mechanic-drivers of the past, the end-users are becoming the technicians as user interfaces disappear. Information technology is something in the back pocket of every good executive today. It is no longer hidden in a dark data center in the bowels of a large building. Businesses today that rely on an old model for information technology management without providing their employees and decision makers a level of transparency in acquiring vital and meaningful information will most certainly fall behind — just as those who failed to embrace the technology of the telephone or the automobile fell behind in the past.
IT Management in Transition
Historically IT management has been concerned with using specific, very technical tools to manage disparate islands of technology. Each tool had its own very specific user interface and clearly defined purpose. Some tools managed performance. Others managed operations. Still others monitored the overall health of networks and infrastructure. The tools were simply that – tools set to a very narrowly defined purpose. While this situation allowed for somewhat effective, siloed management of specific IT tasks, it also created vast amounts of data that, on its own, had little value for business decision-makers and, arguably, for the business as a whole.
This situation, where end-users operate with a disparate set of both mental models and user interfaces, is referred to as “information dissonance” by the US. Department of Defense, Defense Technical Information Center (“Information Dissonance, Shared Mental Models and Shared Displays: An Empirical Evaluation of Information Dominance Techniques”, 1998). It’s not an optimal management scenario! However, according to the same Department of Defense report, “effective team performance could be enhanced by providing teams with sufficient information to build a shared mental model of each other’s tasks and goals, either through direct instruction, or through provision of shared displays.” Simply replace the word “team” with “business” in this powerful statement and it is easy to see that a holistic approach to IT management for business that includes a shared vision and end-user experience can greatly benefit business as well as it does defense.
Today mechanisms such as Business Service Management (BSM) and the use of Configuration Management Databases (CMDBs) can help to reduce the level or information dissonance by modeling the relationships between IT services and business into shared visions and user interfaces. Process frameworks like ITIL® drive a transformation of technologically-focused user interfaces into more ubiquitous and virtually invisible atomic user interfaces. Just like atoms, these interfaces can be imbedded everywhere and yet remain unseen as discrete units. Likewise the resulting atomic user interfaces are composed of small, virtually invisible parts that can be imbedded directly and imperceptibly into workflow. In the end, the future promises more automated tools for practical business decision-making driven by model-driven structures like metadata. In the not-too-distant future, key IT decisions will be promoted into the overall, organic business management workflow. With shared models and transparent, ubiquitous user interfaces, we may well soon witness the total absorption of IT into the typical day-to-day running of business.
Ambient Findability and Data Overload
So how might decision makers actually access all of this meaningful information seamlessly? As I outlined in the last installment, appropriate context of information involves three main qualities:
-
Findability (Where is it?)
-
Comprehension (What is it?)
-
Perception (What does it mean to me?)
Note that the first element in adding context to information is findability. You must first be able to access information before you can ever hope to determine its context. A properly executed metadata model makes findability almost a transparent element. It is built in. This quality alone is extremely important.
In his book Ambient Findability, Peter Morville describes ways in which people – including knowledge workers — have worked to “combine streams of complex information to filter out only the parts they want” (2005). Using the World Wide Web as an example, Morville explains that knowledge workers (or even the humble web surfers we all have become) have now demanded that information technology provide us all with an ambient level of findability. Simply browse the Web and you can find information about anything. However, it is another business entirely to address the issues of the comprehension or perception of this information – let alone its accuracy. Whether it is on the Web or among knowledge workers this problem is the same.
Clearly, the sheer volume of information now available with or without any useful context creates new issues for knowledge workers. The volume of information alone makes it more troublesome to contextualize. Morville cites “Mooers’ Law”:
“An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information rather than for him not to have it” (1959).
While it may sound like stating the obvious, the implications of this simple statement lead directly towards our historical observations about technology in general. Calvin Mooers, the author of the statement above was both a computer pioneer and entrepreneur. He knew the value of information technology in the right context – especially for business. He also could see the perils of information overload. Once again, using a metadata model can help, but there is always a threat of MetaChaos. Of course, it can be avoided, as well.
The next articles will focus on:
-
Dealing with ‘MetaChaos’
-
The melding of operations and management
About the Author
Ian Rowland is a Senior Director of Product Management at ASG Software Solutions. He is responsible for the definition of ASG’s enterprise metadata repositories, ASG-Rochade ™ and ASG-Manager ™ Products, for the creation and implementation of product launch and delivery plans and for creation and management of partner relationships. Originally from the U.K., Rowlands is a standing member of the British Computer Society and a Chartered I.T. Professional.